
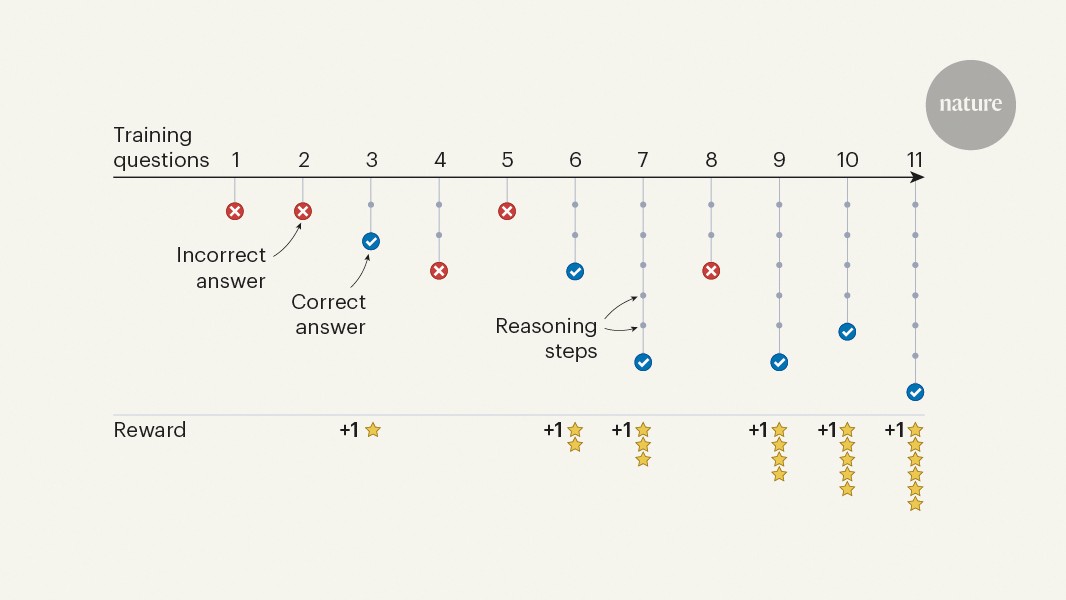
Cuando un estudiante se encuentra con un problema matemático desafiante o un programador necesita escribir un algoritmo complejo, rara vez lo resolverá todo de una sola vez. En cambio, razonarán a través de la tarea, anotando notas y pasos intermedios para llegar a una solución final. Del mismo modo, los modelos de lenguaje grande (LLMS) – sistemas de inteligencia artificial (IA) que procesan y generan lenguaje humano – funcionan mejor en tareas complejas cuando escriben su proceso de razonamiento antes de borrar una respuesta que cuando no1. En papel de Naturalezael equipo de Deepseek AI2 Los informes de que los LLM se pueden incentivar para aprender a razonar sin que se muestren ejemplos de trayectorias de razonamiento humano, utilizando un proceso de prueba y error llamado aprendizaje de refuerzo.



