

Capacitación con tuberías de datos automatizadas
Voyager se basa en el anterior de Tencent Hunyuanworld 1.0lanzado en julio. Voyager también es parte del ecosistema «Hunyuan» más amplio de Tencent, que incluye el Hunyuan3d-2 modelo para el texto a la generación 3D y el previamente cubierto Hunyuanvideo para síntesis de video.
Para entrenar a Voyager, los investigadores desarrollaron un software que analiza automáticamente los videos existentes para procesar los movimientos de la cámara y calcular la profundidad para cada cuadro, lo que elimina la necesidad de que los humanos etiqueten manualmente miles de horas de metraje. El sistema procesó más de 100,000 videoclips de grabaciones del mundo real y de los renders de motor Unreal antes mencionado.
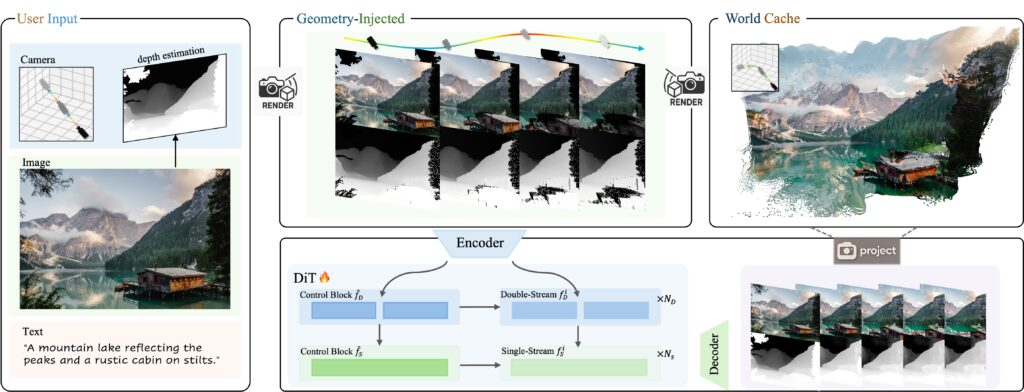
El modelo exige una potencia informática grave para ejecutarse, lo que requiere al menos 60 GB de memoria GPU para una resolución de 540p, aunque Tencent recomienda 80GB para obtener mejores resultados. Tencent Publicado los pesos del modelo En la cara abrazada e incluyó un código que funcione con configuraciones individuales y múltiples de GPU.
El modelo viene con notable restricciones de licencia. Al igual que otros modelos Hunyuan de Tencent, la licencia prohíbe el uso en la Unión Europea, el Reino Unido y Corea del Sur. Además, las implementaciones comerciales que atienden a más de 100 millones de usuarios activos mensuales requieren licencias separadas de Tencent.
En el Escoras Benchmark desarrollado por los investigadores de la Universidad de Stanford, Según los informes, la Voyager logró el puntaje general más alto de 77.62, en comparación con 72.69 para Wonderworld y 62.15 para Cogvideox-i2v. Según los informes, el modelo se destacó en el control de objetos (66.92), la consistencia del estilo (84.89) y la calidad subjetiva (71.09), aunque colocó en segundo lugar en el control de la cámara (85.95) detrás del 92.98 de Wonderworld. WorldScore evalúa los enfoques de generación mundial en los criterios múltiples, incluida la consistencia 3D y la alineación de contenido.
Si bien estos resultados de referencia autoinformados parecen prometedores, la implementación más amplia aún enfrenta desafíos debido al músculo computacional involucrado. Para los desarrolladores que necesitan un procesamiento más rápido, el sistema admite una inferencia paralela en múltiples GPU utilizando el Marco XDIT. Ejecutar en ocho GPU ofrece velocidades de procesamiento 6.69 veces más rápido que las configuraciones de una sola GPU.
Dada la potencia de procesamiento requerida y las limitaciones para generar «mundos» largos y coherentes, puede pasar un tiempo antes de que veamos experiencias interactivas en tiempo real utilizando una técnica similar. Pero como hemos visto hasta ahora con experimentos como el genio de Google, potencialmente estamos presenciando pasos muy tempranos en una nueva forma de arte interactiva y generativa.



